Permalink ↓
How to know if your Linux machine is on 5GHz WiFi and what channel
Published: Fri Dec 09 2022 00:00:00 GMT+0000 (Coordinated Universal Time)
In a terminal, just issue:
iwconfig
And for one network interface you will get something like this, where "5.18GHz" indicates you're on the higher band:
wlp1s0 IEEE 802.11 ESSID:"My dual band WiFi"
Mode:Managed Frequency:5.18 GHz Access Point: FF:FF:FF:FF:FF:FF
Bit Rate=6 Mb/s Tx-Power=20 dBm
Retry short limit:7 RTS thr:off Fragment thr:off
Power Management:on
Link Quality=51/70 Signal level=-59 dBm
Rx invalid nwid:0 Rx invalid crypt:0 Rx invalid frag:0
Tx excessive retries:0 Invalid misc:0 Missed beacon:0
If you want to know what channel you're on you can install the iw command e.g. with apt on Ubuntu and get something like this:
Interface wlp1s0
ifindex 3
wdev 0x1
addr ff:ff:ff:ff:ff:ff
type managed
wiphy 0
channel 36 (5180 MHz), width: 80 MHz, center1: 5210 MHz
txpower 20.00 dBm
multicast TXQ:
qsz-byt qsz-pkt flows drops marks overlmt hashcol tx-bytes tx-packets
0 0 0 0 0 0 0 0 0
which indicates channel 36 in this case. But I guess that was probably obvious from the frequency anyway in the previous query?
Source: https://superuser.com/questions/485588/determine-channel-of-wireless-interface
Permalink ↑
Permalink ↓
Pipewire got the sound back for YouTube videos on Ubuntu 22.04
Published: Mon Nov 14 2022 00:00:00 GMT+0000 (Coordinated Universal Time)
Sound disappeared in Firefox sometimes and did not come back, while playing YouTube videos. Only recourse seemed to be to restart the computer! I got it back by installing a new sound system called pipewire, see instructions here:
https://ubuntuhandbook.org/index.php/2022/04/pipewire-replace-pulseaudio-ubuntu-2204/
Seems to be a problem for a certain Intel chipset?
Discussion here:
https://askubuntu.com/questions/1406874/youtube-freezing-videos-in-fresh-22-04-installation
Permalink ↑
Permalink ↓
encfs needs some tweaks to work on Ubuntu 22.04, better to replace it
Published: Mon Nov 14 2022 00:00:00 GMT+0000 (Coordinated Universal Time)
encfs is an old deprecated way of encrypting a volume. It may have problems working on newer Linuxes, unless you allow OpenSSL to use old stuff. More info here:
https://askubuntu.com/questions/1405656/encfs-segfault-in-version-22-04
It's better to replace encfs with something better, such as the pretty much standard luks/luks2.
Permalink ↑
Permalink ↓
Can you trust sites that furnish apks for Android?
Published: Mon Nov 14 2022 00:00:00 GMT+0000 (Coordinated Universal Time)
Well, the answer from me is that I don't know but some seem more trustworthy than others. apkmirror has a known team behind while e.g. apkpure does not.
According to this comparison, apkpure has had malware included, and no one knows who's behind the site:
https://www.slant.co/versus/7899/22173/~apkmirror_vs_apkpure
So if choosing between these two, https://apkmirror.com seems the better option. If it's good enough, no idea.
Permalink ↑
Permalink ↓
Got access to a luks2 encrypted USB boot drive that borked
Published: Sat Aug 20 2022 00:00:00 GMT+0000 (Coordinated Universal Time)
Preliminary notes. I wasn't exactly sure what I was doing here. Maybe it was already mounted and that was the problem. Anyway, files saved.
A USB boot disk with luks2 and LVM refused to boot. Needed to save the files from it.
I connected it to another computer.
Used this to figure out its /dev/sd(letter)(number):
sudo lsblk -o NAME,FSTYPE,SIZE,MOUNTPOINT,LABEL
It was /dev/sdc6. Opened it into a logical volume name that I made up, "my_encrypted_volume":
sudo cryptsetup luksOpen /dev/sdc6 my_encrypted_volume
Made a local mount point in the home directory
mkdir -p mnt/rescue
Mounted it there:
sudo mount /dev/mapper/my_encrypted_volume mnt/rescue
And that did not work for me, it may work for you. I got an error message about:
mount: unknown filesystem type 'LVM2_member'
I figured out its LVM(?) name by issuing:
sudo pvscan
Then took that name, e.g.: "root-vg" and issued:
sudo vgchange -a n root-vg
sudo vgchange -a y root-vg
…to make Linux mark it as inactive, then active again. Got this info from this page:
https://svennd.be/mount-unknown-filesystem-type-lvm2_member/
And then it could be mounted and then accessed under $HOME/mnt/rescue. Copied files off of it with:
rsync -rh --progress mnt/rescue/path/to/files /media/username/mybackudisk/backups/
The lsblk dance I got from https://askubuntu.com/questions/182446/how-do-i-view-all-available-hdds-partitions .
Permalink ↑
Permalink ↓
Simple 3 point lighting rules for a talking head
Published: Thu Jun 09 2022 00:00:00 GMT+0000 (Coordinated Universal Time)
Simple 3 point lighting rules for a talking head. I took these from a video, published here as notes for myself only. Don't take lighting advice from me without double checking!
First light, right or left (maybe camera's left best?). 45 degree angle, a bit above the subject if you want Rembrandt's triangle. No sharp light, since it casts sharp shadows
Second light, same setup but opposite side. Less light.
Third light, directly opposite first light but higher up, out of shot.
Background should be darker on the more lit side of the face. Background overall in between the brightness of the left and right side of the face of the subject.
Background can have complement colours, each side.
Source: https://www.youtube.com/watch?v=AUmu1e78Bhk
Permalink ↑
Permalink ↓
How to make a systemd Linux check its boot disk on startup
Published: Wed Jun 01 2022 00:00:00 GMT+0000 (Coordinated Universal Time)
To make a systemd Linux check its boot disk on startup, you provide a special boot parameter, fsck.mode=force. So in /etc/grub something like:
GRUB_CMDLINE_LINUX_DEFAULT="quiet fsck.mode=force"
And then remember to update grub.
Source: https://www.cyberciti.biz/faq/linux-force-fsck-on-the-next-reboot-or-boot-sequence/
Permalink ↑
Permalink ↓
How to get one icon per window in the Ubuntu 22.04 dock
Published: Sat May 28 2022 00:00:00 GMT+0000 (Coordinated Universal Time)
Updated 2022-11-26: What seems to work for me now on Ubuntu 22.10 is to install a Firefox extension which then smoothly and a bit worryingly integrates with gnome on my desktop.
The extension can then be installed from here:
https://extensions.gnome.org/extension/1160/dash-to-panel/
Old text:
You have to download dash-to-panel. This can be done by installing gnome extensions manager from the standard repos. Then choose "Browse" and type a search string to find dash-to-panel. Nota bene that gnome extensions manager only presents the first twelve or so search results, so you've got to do a reasonably precise search.
Once installed, you can configure dash-to-panel either from gnome extensions manager or from gnome extensions app.
gnome extensions manager:

gnome extensions app (in Swedish)
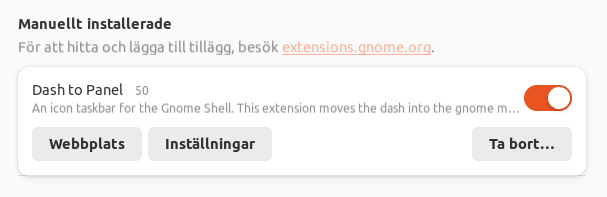
In either one go to dash-to-panel's settings and under "Behavior" select "Ungroup programs" (sorry about the Swedish):
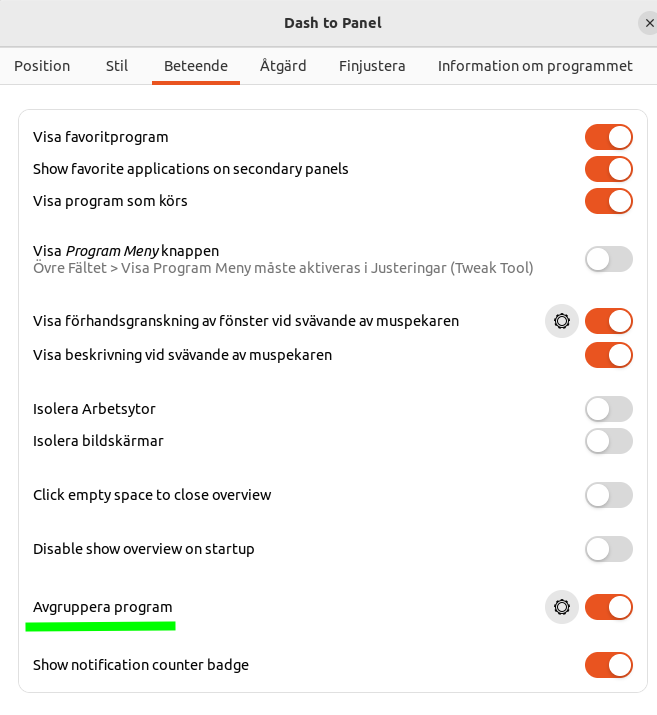
And your dock, if it's vertical will start to look like this:

Permalink ↑
Permalink ↓
Bash — How to give a file to a command without making a file
Published: Thu Apr 14 2022 00:00:00 GMT+0000 (Coordinated Universal Time)
You can use heretext. The syntax seems to be:
commmand <<< $"file contents"
Tested by me. Or use single quotes. See: https://stackoverflow.com/questions/5852643/piping-in-on-the-command-line-simulating-a-file
Permalink ↑
Permalink ↓
Linux — How to get rid of something on screen you don't know where it comes from
Published: Tue Mar 22 2022 00:00:00 GMT+0000 (Coordinated Universal Time)
How to get rid of something (a window) on screen you don't know where it comes from:
xprop _NET_WM_PID
This will get you the process id. At least it did for me. Use:
ps aux
plus grep to find out what the process is. Then kill.
Permalink ↑
Permalink ↓
A temporary diskless desktop Linux
Published: Fri Nov 19 2021 00:00:00 GMT+0000 (Coordinated Universal Time)
What if you could have a Linux desktop environment that cannot save things to disk because there is no longer any disk? This could be good for knowing that your USB boot stick remains pristine. Add "toram" to the boot parameters without the quotes.
Permalink ↑
Permalink ↓
How to shrink a bootable disk image
Published: Wed Nov 10 2021 00:00:00 GMT+0000 (Coordinated Universal Time)
This method worked for me. I had a 64GB disk image made from a botable USB stick, and I wanted to shrink it down so that it could fit on 16GB memory sticks.
https://superuser.com/questions/610819/how-to-resize-img-file-created-with-dd#comment2505407_1583784
Short summary in case of bit rot:
lsblk
sudo umount <the device from lsblk>
dd if=<the device from lsblk> of=/path/to/file/myimage.img
sudo modprobe loop
sudo losetup -f
That would give you the next free loop device number. If it were 25, then:
sudo losetup /dev/loop25 myimage.img
sudo partprobe /dev/loop25
sudo gparted /dev/loop25
Resize inside of Gparted
Then:
sudo losetup -d /dev/loop25
fdisk -l myimage.img
Check the end block and the block size from that command. If end block is 9181183 and block size is 512, then issue:
truncate --size=$[(9181183+1)*512] myimage.img
Permalink ↑
Permalink ↓
Gymnasieingenjör is "Certified upper secondary school engineer"
Published: Sun Nov 07 2021 00:00:00 GMT+0000 (Coordinated Universal Time)
A Swedish degree that I never figured out what it was called in English, apparently is supposed to be called "Certified upper secondary school engineer". So that's one for your CVs, in case you did that extra year.
Permalink ↑
Permalink ↓
And this is what solved my sound problem this time (Ubuntu)
Published: Sat Nov 06 2021 00:00:00 GMT+0000 (Coordinated Universal Time)
Pulseaudio reported a dummy device, alsamixer said there were devices, but they had no controls. Ubuntu 21.10 on a laptop with a graphics card.
Anyway, what solved it was to add this to /etc/default/grub, to the GRUB_CMDLINE_LINUX_DEFAULT line:
snd_hda_intel.dmic_detect=0
And then:
sudo grub-mkconfig -o /boot/grub/grub.cfg
Permalink ↑
Permalink ↓
Could you with a soldering iron disable radio (Bluetooth/WiFi) on a Raspberry Pi 4B?
Published: Tue Nov 02 2021 00:00:00 GMT+0000 (Coordinated Universal Time)
Could you with a soldering iron disable radio (Bluetooth/WiFi) on a Raspberry Pi 4B?
I suspect it works if you get rid of this little diode inside the red frame on my RPi.

https://forums.raspberrypi.com/viewtopic.php?
Permalink ↑
Permalink ↓
How to increase the scroll of the mouse wheel on Ubuntu Linux 21.04
Published: Sun Oct 31 2021 00:00:00 GMT+0000 (Coordinated Universal Time)
One option that works for me is imwheel. It is in the standard repositories.
In $HOME/.imwheelrc one can put something like:
"^.*Chrome.*$"
None, Up, Button4, 6
None, Down, Button5, 6
"^.*Firefox.*$"
None, Up, Button4, 7
None, Down, Button5, 7
".*"
Control_L, Up, Control_L|Button4
Control_L, Down, Control_L|Button5
Control_R, Up, Control_R|Button4
Control_R, Down, Control_R|Button5
The values 6 and 7 refer to increased scroll speed.
Permalink ↑
Permalink ↓
How to use Mastodon's RSS feed as a source for a (static) blog
Published: Sun Jan 19 2020 00:00:00 GMT+0000 (Coordinated Universal Time)
If you publish to Mastodon, you can publish stuff further by parsing the RSS feed of your account.
The naïve and quick way of doing this is to just parse the RSS and create one file (or two if there is an attachment) per item and bam, done.
Edits
However what if an item has been edited? The way Mastodon deals with this is to delete the old item and issue a new one with a new guid.
If your blog is going to stay consistent with this, it has to delete the old item as well. Ok, easy-peasy, just delete files that are not in the RSS feed. But wait, maybe older files are not anymore covered by the RSS feed. Feeds often limit their contents either to a maximum number of items or to newer items only.
So the code has to detect if an item on disk is missing from the feed, but also check if the file is new enough that it ought to be covered by the feed. That can be done by checking if the file is older than the last item in the feed, in which case we should probably keep the file.
Timestamps
But how do you get info on what timestamp the file has? It must have been stored in connection with the file, it could be in the front matter, it could be in a separate index file or it could be encoded into the file's filename.
If you put it into a separate file, one needs the info in that to be consistent with the files, i.e. one needs to do it in an atomic way. Too much work!
If you put it into the front matter of a file, then all files must be opened and read. So the easiest thing seems to be to put it in the file name. Then as the feed is loaded, you can check for the oldest item in the feed, and disregard all files whose filenames indicate an older creation date than that.
Permalink ↑
Permalink ↓
Tools for static blogging, Activitypub and the Fediverse
Published: Sat Jan 11 2020 00:00:00 GMT+0000 (Coordinated Universal Time)
Over Christmas 2019 I decided to port my blog away from the all-in-one CMS I'd used for 15 years (Plone).
I turned it into a static blog, using activitypub on the way to make and push content with a GUI on Android and desktop. I discovered some great projects and apps on the way.
Somewhat covered in this post are ActivityPub, Mastodon, Pump.io, Plume, Tusky, AndStatus, Subway Tooter, Metalsmith, Pumpa and Plone .
What I migrated from
Feel free to skip this section unless you're into the Plone CMS or porting systems in general :)
My blog had been running on Plone for 15 years, but initial tests over Christmas of upgrading it and its plugins to the latest and greatest version of Plone indicated it would be quite some work on all kinds of levels. I had already done a complex upgrade of it once before, a couple of years ago.
Plone is a great system, I made my living consulting, programming its products and teaching it for 10 years. But one would not necessarily be wrong if one said that Plone is the most complex CMS on earth. It has some very powerful principles such as content frameworks, acquisition, multiple inheritance, interfaces & adapters (either in XML files or somewhere in the code), a great workflow engine, a fine grained permissions system and event listeners that when they are all brought together can create a multi dimensional contraption of zen-like complexity (if that makes sense). It also has a great search engine.
Plone is object oriented to the core with an object database, and with all of that come the usual problems with objects: There are so many ways they can be configured and used. When porting from one blogging framework in Plone to another, one can export to XML files, and then reimport them to the new system. However if no one has written these exports and imports, you will need to delve into how the objects actually work.
From the point of the reader or author, a blog post is just a piece of text and some pictures. But for Plone or any similar system it is an object of multiple inheritance which is workflowable and has data on it separated into different categories such as metadata. It may to try to to be compliant with different standards such as Dublin core. The data may be stored on the object as attributes with names you can figure out, or they may be stored in dictionaries with weird top key names. Maybe you should call methods instead of accessing attributes directly. Maybe you should create an accessor object that accesses the objects for you. Maybe the document object should be configured with an accessor object that is pluggable. And so on, you get the picture.
When different people make different objects with different ideas of how they should work, and put them all into the same system, you may get a combinatorial explosion of how things could interact and you need to read up on an understand each one to make them work together. Files on the other hand have at least a limited behavior.
Also the sheer age of Plone and its underlying Zope server has created archeological layers of coding styles and patterns.
In fact, the Zope ecosystem has such a fierce reputation that a guy has made a joke package called "zope.cooties" that you can include in your project to discourage people from reading your code, asking question or submitting pull requests:
https://pypi.org/project/zope.cooties/
On top of that or rather underpinning it are different versions of python and different ways of installing software in the python universe. Dealing with old stuff, sometimes you need to know what month package versions are in, to know what to use, especially when the stuff goes out and tries to install stuff for you.
https://stackoverflow.com/questions/6344076/differences-between-distribute-distutils-setuptools-and-distutils2
Version pinning mitigates a lot of this, but sooner or later the complex systems starts "leaking" and you are pulling in the wrong kitchen sink.
As I was trying to upgrade all these different things I ended up not being able to estimate how much there was left to do. I realised I was not comfortable with having all my content in a system I could not touch. So my Plone had to go.
I tried using wget and httrack to mirror my Plone site but because of CGI parameters you can get into permutations of urls that just go on. In hindsight I could have turned off CGI params, but in the end I just asked Plone through ZCatalog queries what urls it has for documents and images, and I wrote a downloader to fetch those specific urls.
Static blogging
Ok, now I had 2900 files. I decided to go completely the other way from Plone, in order to cover as much conceptual ground as possible, and learn. Plone is super-dynamic, so let's go for static blogging! I will not end up losing control of a bunch of static files after all.



Static blogging has become all the rage with systems such as Jekyll, Nikola, Pelican, Next, Hugo and Gatsby. I chose however Metalsmith for the initial porting. Metalsmith is just one big pipeline and hence conceptually very simple.
Remember I was tired of complex stuff, and if everything flows in a pipeline there will be no spooky interaction at a distance, or the multi dimensional Zen of a Plone request (did I say Plone request? I mean of course Plone multi adapter).
The plugin universe of Metalsmith did not have exactly the stuff I needed, but it is dead easy to make your own plugins and within short time I had made Metalsmith plugins for:
- Extracting dates and other metadata from HTML html-to-keys-metalsmith
- Rewriting element attributes html-attribute-rewriter-metalsmith
- Pagination paginator-metalsmith
- A client side search engine search-index-metalsmith
(These are on a works-for-me quality level and nothing beyond that)
Many, maybe all static blog systems employ a metadata standard called Frontmatter. It allows file to have a section in the beginning with data in e.g. YAML or JSON format, depending a bit on the platform.
Client side search
The client side search engine question was interesting, how do you search a static blog? The answer is you export the search index over to the web browser and have it search everything. I found the most efficient way for me was just to export all contents to the client side in a JSON file. My almost 3000 pages only weighed in at 3MB in plain text and a brute force search of that is instantaneous on both laptop and mobile. There are other more elaborate solutions such as Flexsearch, but the index size turned out to be the limiting factor in my case, so brute-force search on the actual texts worked fine. Flexsearch by default weighed in at 150MB in index size. That size can be trimmed but I guess Flexsearch comes to it's fore for massive amounts of text such as 50'000 documents and upwards and/or sophisticated searches. I just AND together my search words. Other solutions are lunr.js .
Wysiwig publishing to a static blog from desktop or mobile is not a thing, ActivityPub to the rescue
Plone and other similar CMSes have excellent HTML Wysiwyg editors, where you can even just paste in images and they get included. Static blogs afaict generally have nothing. You are supposed to slog away in markdown, make your image links in code and then hit the command line for publishing. Not an option on mobile and not much fun on desktop either. However there are great Markdown and Image helper plugins for e.g. the VS code and Atom text editors.

For VS code there is Markdown Preview Enhanced, Paste Image and Markdown All In One, used by me indeed for this making this post. In fact including images is so easy I may have gone a little overboard…
Making blog posts on mobile
You could go with note taking apps on mobile such as Joplin or Orgzly, but they edit a document tree, and I wanted to push content to my static blog, not having the whole blog on my phone.

But are there any general clients for editing rich content and pushing it to publishing? It turns out there are, such as Tusky, AndStatus and Subway Tooter, and here we are entering the world of federated updates and blogging on the ActivityPub standard.
I have tried out Tusky, AndStatus and Subway Tooter on Android and they all have their pros and cons.
AndStatus can handle a lot of different accounts simultaneously:
…while Tusky seems to only handle one. Tusky looks nicer though and can take photos directly with the camera. Subway Tooter looks a bit worse but can also record video which Tusky cannot.
All three can include an image or video already recorded. Even with the multiple account feature, it seems AndStatus cannot handle services on non standard ports.
What are then the ActivityPub systems that you can push to?
The Fediverse
ActivityPub is a standard widely used in an ecosystem called the Fediverse. The Fediverse is the idea that instead of using global centralized services, we should use many hubs in a federation, where these hubs cooperate to make a service, sometimes similar to let's say Twitter or Facebook.
I think the Fediverse is important. If you have all your social interactions and data through centralized services, you could well lose all your contacts and interactions if a service would stop working. It seems therefore to be prudent to complement the central service with at least a bit of Fediversing.
I believe that digital signatures must be become a more used part in what I have seen of the Fediverse so far, including certificate systems.
However for my blog project and for this post, the interesting part of the Fediverse is that federation means there are standards for communication which means we can use components such as editors and servers any way we want. They are pluggable.
ActivityPub servers

ActivityPub is an open standard for social content. Systems based on it got a lot of attention back in 2013, but it's have now made a comeback. It is about breaking free from centralized services and build up a federated publishing ecosystem.
 Mastodon
Mastodon
The first ActivityPub server system I encountered was Mastodon which is Twitter-like. It limits the post size to 500 characters by default but has excellent support on e.g. Android. I had an account on a Mastodon server and I can now push content to the server with Tusky or the other apps, and then pull it down to my static blog via RSS:
Tusky→Mastodon→RSS→My blog
This may seem a bit like overkill for getting stuff from A to B, but you get the benefit of having Android support for publishing.
 Pump.io
Pump.io
But what if you want longer texts than 500 characters? Blog posts are not tweets after all. There is another ActivityPub server called pump.io which has no default size limits afaict. It is written in javascript while Mastodon is in Ruby. I'd prefer javascript and python and possibly Rust, while I'd like to avoid Ruby and Go (no offense, those are just languages I have less experience with). However how well maintained the systems are will be more important in the end, which I will have to check further into
I had problems using the public pumps, so I set up my own and after some work I can now publish to it from the the desktop client Pumpa. I put my pump server on a high port and most pump.io clients, or indeed any ActivityPub clients cannot handle that, there is no way to put in another port and if you make it part of your identity string, the clients cannot parse it. With the exception of the Pumpa desktop app which does it just fine.
Pump.io is hard to proxy and I have decided to use it only for long blog posts from the Pumpa client on the desktop. I tried to put my pump.io instance on a low port but you basically need to start it as root for that, which I feel is a bit unnecessary. I'd prefer to proxy it behind nginx but the docs advise you not to.
The cool thing is though it does not matter to me what channels I use to reach my blog. They are just conveyors. All roads will lead to Rome anyway, i.e. to my static blog. So I can use pump for some posts and Mastodon or something else for other posts. And there may be even better things in the ActivityPub universe for blogging than Mastodon or Pump…
Getting a feed out of pump.io and learning about OAuth1
Pump.io in contrast to mastodon does not have RSS feeds. Instead you are supposed to use a client that authenticates itself via Oauth1, and gets permissions and pulls down JSON. I tried to install some elaborate feed reader systems but eventually I found some very elegant seven year old Python scripts by Dirk Krause that does the job just fine in few lines of code (check comments in the end for what may need to be changed).
https://gist.github.com/dirkk0/5875461
But wait, there's more!
And once I had done all that work often dealing with old code, it turns out there is a brand spanking new modern ActivityPub blog engine, written in Rust called Plume, that can be installed with Docker, or with Snap or in other ways. Maybe that is the future?
Update: I tried installing from snap, and it cannot understand its own command line arguments as given in the documentation. The command:
$> sudo plume.plm instance new --private --domain plume.example.com --name 'My Plume Instance' -l 'CC-BY'
error: Found argument 'Plume' which wasn't expected, or isn't valid in this context
indicates that command line parsing does not work properly. I will wait with this offering.
 Plume
Plume
Looking more into ActivityPub, is it really suitable for blogging?
Maybe I have not delved deep enough into the ActivityPub standard, but from what I can see from pump.io's JSON output and from the spec itself, it seems to be a lot about pushing one item such as a photo or a piece of text. But for a longer blog post you want multipart. Not sure if that is covered?
For shorter blog posts you can get by with the description of the event + the photo object.
Another standard: MicroPub
https://indieweb.org/Micropub
There is also what appears to be a nascent standard for publishing to blogs. In fact here is a code library specifically made to post to static blogs, in this case Jekyll via GitHub but I guess it would pretty much work for any static blog system with git and frontmatter.
https://github.com/voxpelli/webpage-micropub-to-github
There is one Android client for MicroPub called Indigenous but have not tried it yet.
First (after)thoughts
I'm starting to think that a decent compromise between complex dynamic blogging/CMS systems and static blogs, is to use a dynamic system to manage and make the content, but that the actual publishing goes to static files. A number of CMS systems have such plugins now. However I will soldier on with the new toolchain I built up, for now.
The editing experience was really nice in Plone and I miss it. Blogging gets slower without it. Still it feels good to have the files, and have them under source control. Although Plone has revisions (of course :) ).
This blog post posted via rsync from a git repository that was populated via a Metalsmith pipeline, with as input a Markdown document created with VSCode. All running on Ubuntu Linux 19.10 or 18.04 LTS. The images were taken from the web browser or snagged with Flameshot. Served out statically with Nginx. CSS provided mostly by Twitter Bootstrap for the new blog posts.
Permalink ↑